Increase Traffic, Conversions, Leads, Demand, Revenue from Search
The #1 Organic Marketing platform built for enterprise SEO, Content, and Web teams.















The organic marketing platform for enterprise teams
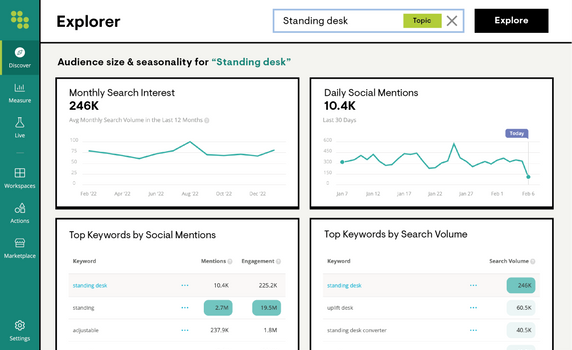
Research Keywords & Competitors
Uncover customer intent across search and social and identify new ways to rank with our index of 20+ billion keywords. Investigate competitor strategies to stay ahead.
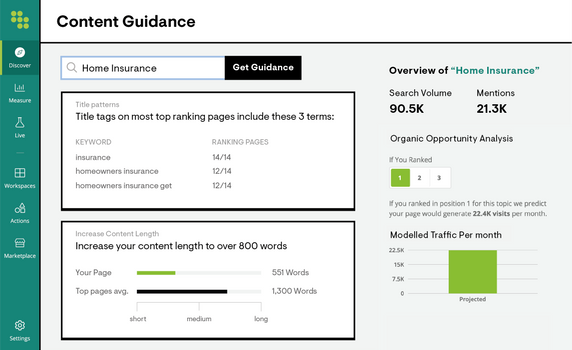
Create Winning Content
Get AI recommendations that provide a blueprint for building high-performing content at scale. Seamlessly brief your content team with integrations with task managers like Asana, Trello, and Jira.
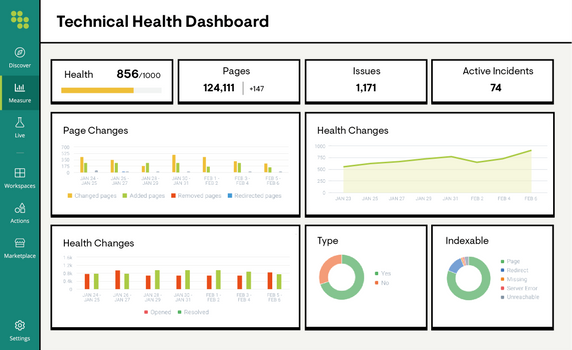
Optimize Site Health
Maximize your website for organic visibility with world-class technical site auditing. Run A/B tests and make changes to any page with push-button changes that instantly go live.
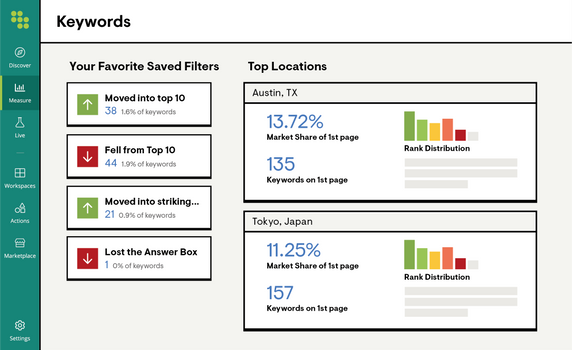
Track Keyword Rankings
Stay on top of your holistic digital visibility with unlimited keyword rank tracking across thousands of locations, global search engines, and device combinations.
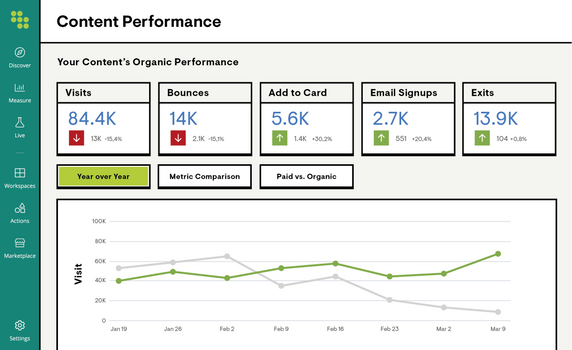
Measure Performance & Share
Report on content performance and know your impact with automated content change detection that correlates your team’s actions with results. Automate reporting with customizable reports.
Rated #1 by analysts, industry experts, and our customers


 Top Leader
Top Leader Highly Rated
Highly Rated
Why people love Conductor

Conductor helped Samsung integrate SEO into its end-to-end content and experience strategy and empowered team members to optimize performance.

Conductor helps us outperform our competitors and serve our target audience with great content. It’s incredibly powerful to be able to diagnose issues and manage sitehealth, content strategy,and SEO all in one place.

Conductor is extremely valuable for us. It gives us a better and more comprehensive understanding of our online performance.
Conductor integrates with your entire tech stack

Trusted by the world’s leading marketing teams




One company. Two missions.
We believe a great company has a positive impact on the world and on the people who build it.
Empower brands to transform their wisdom into marketing that helps people
Everything we do at Conductor is driven by our mission to help you help your customers. Thousands of marketers use our platform to create and optimize content, so it gets found, answers questions, and solves problems for real people.

Transform the workplace into a force that helps people grow
We’re not just here to do a job. We’re here to make an impact — on our customers, on each other, and our industry. People-first is a driving force for every decision we make as a company.
